Machine Learning Models
Introduction
In this article, we will demystify the term model and explore the evolving landscape of machine learning tools. We will also cover the difference between classical models and modern LLMs and show you the tradeoffs between running models locally, in the cloud or via an API.
Picking the right ML tool for the job is where we want to get to at the end, instead of plugging everything into a ChatGPT terminal 😝 If you’re a software developer, system architect or tech-curious builder wondering how to integrate ML wisely, this is for you.
There is also a heavy focus on examples in Python, both for generating models and using them. If you don’t know Python, then do still read on. Hopefully, you’ll get inspired to learn Python as well as discovering the underpinnings of modern AI!
Resources or TLDR
Don’t want to read this or don’t have the time. Here’s a list of resources I reference in this document (or you might find generally useful):
Communities
- Kaggle - The Largest AI and ML community
- Hugging Face - The platform where the machine learning community collaborates on models, datasets and applications.
Tools
- Open Router Models - Access any hosted LLM model (from GPT to DeepSeek) from this one interface!
- Github Models - Find and experiment with AI models for free
- Jupyter - ML engineers and data scientists will use this tool to write Python code that interfaces with ML models.
- PyTorch, TensorFlow and JAX - Most complex models are built on PyTorch, TensorFlow or JAX. The backbone of modern AI!
- scikit-learn - Python library for building most types of ML model. Less focus on neural nets (like PyTorch), more on models such as Random Forest.
Learning
- W3Schools Machine Learning course - Lots of getting-started style examples
- Google Machine Learning Education - Highly recommended ML courses from Google
- StatQuest YouTube channel - The best beginner-friendly ML YouTube channel
- Wikipedia’s Machine learning Models - The “official” list of model types, as penned by academics and the data-science community.
- Machine Learning for Kids - We’ve all got to start somewhere!
- There’s also free ML courses from Harvard, IBM and FreeCodeCamp
What is a Model?
In Machine Learning, a model refers to a mathematical construct trained to make decisions or predictions based on input data. The term comes from mathematics and statistics, where a model represents a simplified abstraction of a real-world process, created from datasets. Once you’ve trained or created a model, you can then use it to create new data or predictions from an input that it’s never seen before 🪄
GPT, Gemini and Claude are examples of Large Language Models and are perhaps the most well-known type of ML Model (circa 2025) by the general public (more commonly referred to as “ai eye”). However, these are very extreme examples and represent the high end in a spectrum of model complexity
Before AI became known for chatbots and image generators, professionals who dealt with data (such as data scientist) used and still do use a variety of machine learning (ML) models to make predictions, detect patterns or sort information. These models were usually small, focused and trained on structured data like spreadsheets or databases.
Types of ML Models
Here are the major types of ML model:
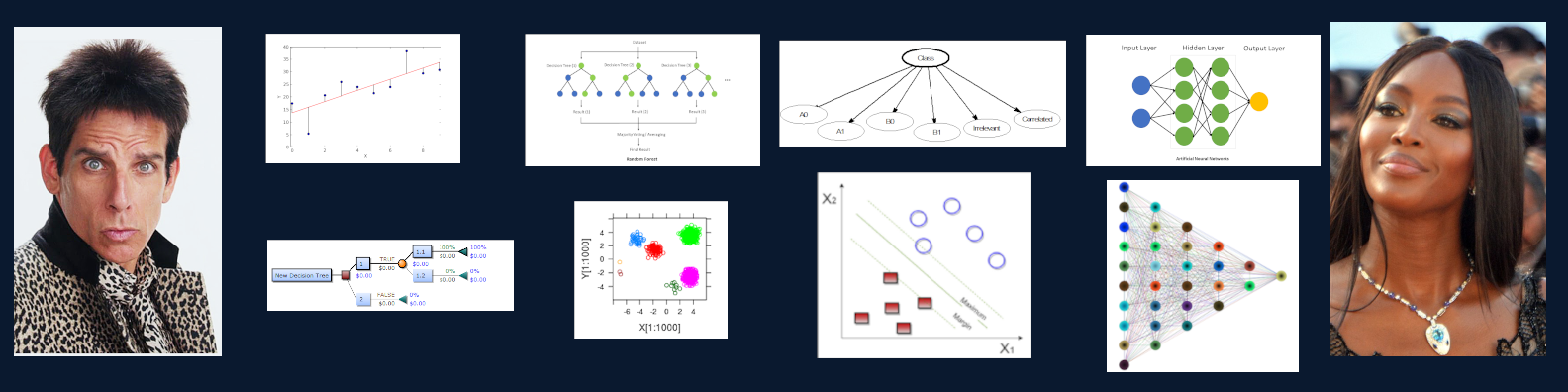
1. Linear Models – The Straight-Line Thinker
Draws a line or curve through data points to spot trends and make predictions.
See W3Schools Python explainer on Linear Regression.
- Used for: Forecasting sales, predicting prices
- Strength: Simple, fast, easy to interpret
- Weakness: Can’t handle complex relationships
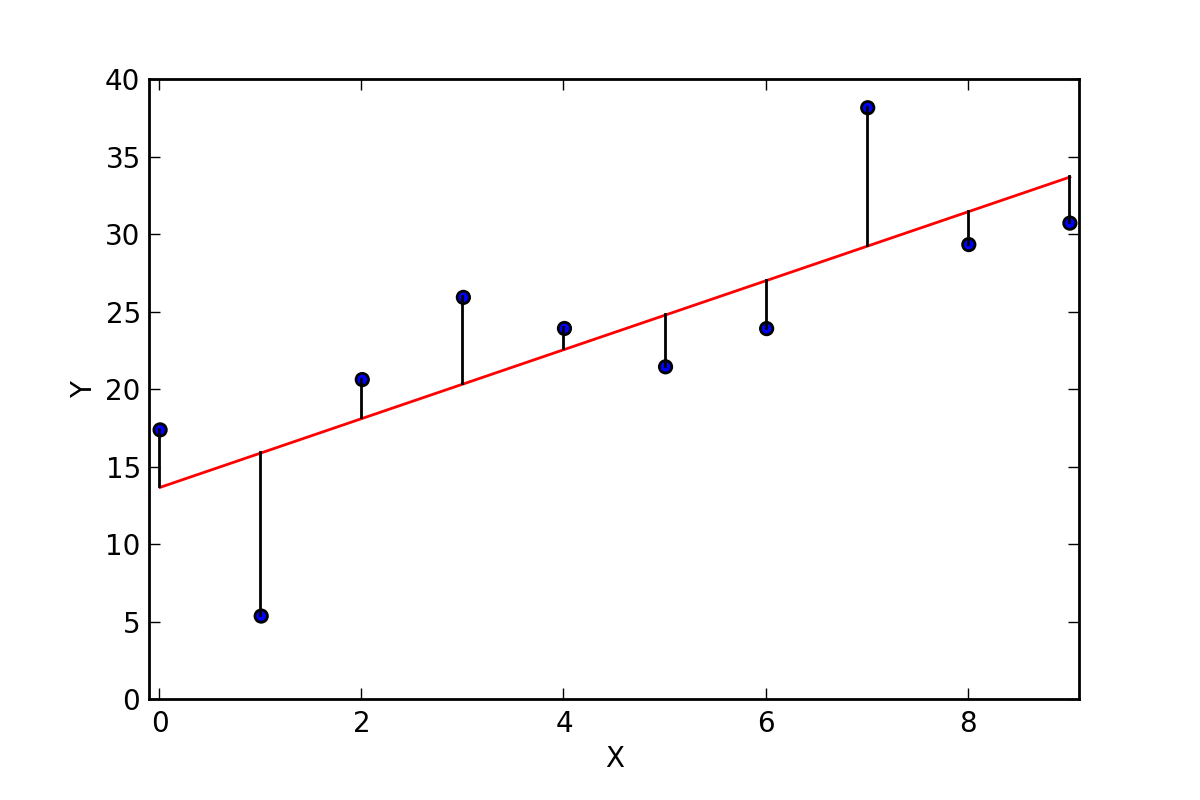
2. Decision Trees – The Flowchart Brain
Asks a series of yes/no questions to make a decision.
See W3Schools Python explainer on Decision Tree.
- Used for: Loan approval, medical diagnoses
- Strength: Easy to understand and explain
- Weakness: Can overfit and make decisions that don’t generalise
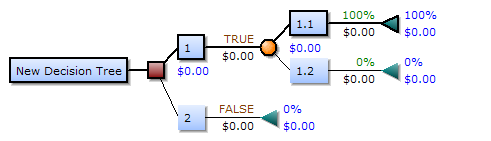
3. Random Forests – The Crowd of Flowcharts
Builds many decision trees and combines their answers to improve accuracy.
Datacamp has a nice explainer of Random Forest.
- Used for: Risk scoring, product recommendations
- Strength: More accurate and robust
- Weakness: Harder to explain decisions
4. Clustering Models – The Natural Group Finder
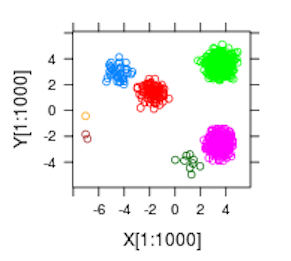
See this medium article for a practical Python example.
Groups similar things together without knowing the labels ahead of time.
- Used for: Customer segments, user behavior patterns
- Strength: Great for discovery
- Weakness: Can be sensitive to noise or unclear groups
5. Naive Bayes – The Probability Calculator
Makes predictions based on how likely something is, given past data.
- Used for: Spam filters, topic classification
- Strength: Very fast
- Weakness: Can oversimplify complex problems
6. Support Vector Machines (SVMs) – The Border Drawer
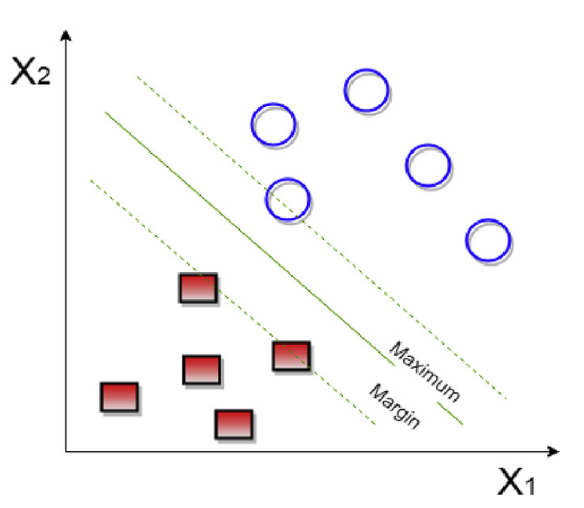
Draws the best dividing line between different categories in your data.
See this medium article for a Python example.
- Used for: Image classification, face detection
- Strength: Precise with clean data
- Weakness: Not great with lots of messy or overlapping data
7. Neural Networks – The Brain-Inspired Pattern Learner
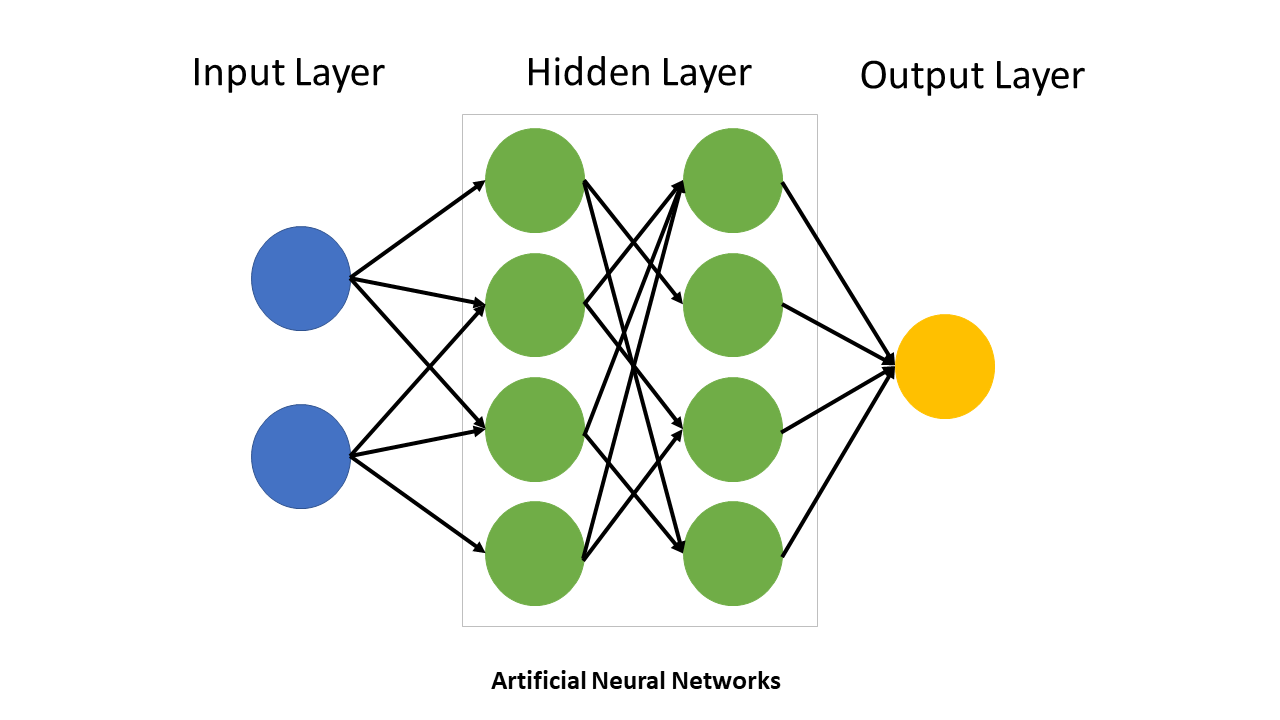
Mathematical models inspired by biological neural networks, consisting of interconnected nodes (“neurons”) organised in layers that process and transform input data.
See Real Python article on how to build a Neural network in Python
- Used for: Pattern recognition, classification, prediction
- Strength: Can learn complex relationships
- Weakness: Need careful tuning, can be unstable
8. Deep Learning – The Advanced Pattern Master
Deep learning refers to neural networks with many layers (“deep” architecture). These additional layers allow the network to learn increasingly complex features from data automatically. LLM models such as GPT and Gemini fall into this category.
- Used for: Computer vision, language models, speech recognition, game AI
- Strength: Learns complex patterns automatically, state-of-the-art performance
- Weakness: Needs massive data/compute, complex to train, black box behavior
Common types include CNNs (for images), Transformers (for language), RNNs (for sequences) and GNNs (for network data).
Summary
| Model Type | Example Use Case | Can it Handle Complex Data? | Needs Lots of Data? | Easy to Understand? |
|---|---|---|---|---|
| Linear Model | Predicting house prices | No | No | Yes |
| Decision Tree | Loan approval | Some | No | Yes |
| Random Forest | Fraud detection | Yes | Medium | Kind of |
| Clustering | Market segmentation | Some | Medium | Sometimes |
| Naive Bayes | Spam detection | No | No | Yes |
| SVM | Face detection | Yes | Medium | No |
| Neural Network | Voice or image recognition | Yes | Yes | No |
| Deep Learning (Transformers, CNNs) | Language, vision, etc. | Yes | Yes (lots) | Very hard |
Choosing the Right Model for the Job
In this section, we are assuming that you have a task but don’t know what type of ML model you need (or maybe you don’t need one). It lists out some ML-type tasks and the sort of model you might want to employ for that task.
If your data is structured (tables, numbers, categories):
Use classical ML models like:
Examples:
- Predicting churn from customer data
- Scoring leads in a CRM
- Classifying transactions as fraud or not
✅ Fast
✅ Explainable
✅ Can run locally or in the browser
❌ Not great for messy or unstructured input
💡 If the data fits in a spreadsheet, you probably don’t need a neural net.
📄 If your input is text and the output is a simple label:
Use smaller NLP models (not full LLMs):
Examples:
- Categorising support tickets
- Sentiment analysis
- Spam detection
✅ Lightweight and fast
✅ More accurate than old-school methods
❌ Doesn’t generate language, just classifies
💡 You don’t need ChatGPT to decide if a tweet is angry or not.
🖼 If you’re working with images or video:
Use vision models like:
- ResNet / MobileNet / EfficientNet (for image classification)
- YOLO / Detectron2 (for object detection)
- CLIP / BLIP (for image + text tasks)
Examples:
- Flagging inappropriate images
- Reading license plates
- Matching screenshots to UI components
✅ Purpose-built and efficient
✅ Can run on phones or edge devices
❌ Needs labeled image data to train
🎙 If your input is audio or speech:
Use audio models:
Examples:
- Transcribing calls
- Voice assistants
- Reading text aloud
✅ Highly accurate models are available open-source
✅ Works well offline with the right setup
❌ Audio data can be large and tricky to process
💬 If you need language generation, summarization or reasoning:
Now you’re in LLM territory:
- GPT-4 / Claude 3 / Gemini → commercial APIs
- LLaMA / Mistral / Phi-3 → open-source options
- Use tools like OpenRouter, Ollama or vLLM for access
Examples:
- Summarising a legal document
- Explaining code
- Writing email drafts or documentation
- Chatbots with memory and logic
✅ Extremely powerful
✅ Very general-purpose
❌ Can be expensive
❌ May hallucinate or go off-topic
❌ Overkill for small classification tasks
💡 Use LLMs for jobs that involve language reasoning.
Decision Table: What Model Should I Use?
| Task Type | Recommended Model Type | Example Tool |
|---|---|---|
| Predict from tabular data | Decision Tree | XGBoost, LightGBM |
| Classify short texts | NLP | DistilBERT, fastText |
| Summarize/generate text | LLM | GPT, Claude, Mistral |
| Understand images | CNN | YOLO, ResNet, BLIP |
| Transcribe speech | ASR (Automatic Speech Recognition) | Whisper |
| Group similar users | K-means Clustering | Scikit-learn |
| Detect sentiment in reviews | NLP | RoBERTa |
| Write SEO blog posts | LLM | GPT-4, Claude 3 |
Final Advice: Use the Smallest Model That Works
You wouldn’t call a rocket scientist to fix a leaky tap and you shouldn’t call an LLM when:
- A few
ifstatements would do - A cheap model can do it faster
- You care about speed, cost or explainability
But sometimes LLMs are great. If:
- The task involves nuance, ambiguity or creativity
- You need a prototype right now
- It’s a small task and tokens are cheap
… then go ahead and use the LLM. Just know there’s a whole toolbox behind it and sometimes a hammer really is better than a sledgehammer.
Acquiring models from Hugging Face
Hugging Face hosts a wide range of machine learning models, especially those built with deep learning frameworks like PyTorch, TensorFlow and JAX.
All the models are free or open source, but you will need to provide the compute resource to run them on. Depending on the size of the model, this may be expensive.
Here’s what Hugging Face does and does not host:
| Model Type | Hosted on Hugging Face? | Notes |
|---|---|---|
| Transformers (LLMs) | ✅ Yes | Hugging Face’s core focus (e.g. GPT-style, BERT, LLaMA) |
| CNNs for vision | ✅ Yes | Models like ResNet, YOLO and CLIP |
| Audio models | ✅ Yes | Whisper, wav2vec2, TTS (text-to-speech) |
| Multimodal models | ✅ Yes | e.g. Flamingo, BLIP (image + text) |
| Small/efficient LMs (SLMs) | ✅ Yes | e.g. DistilBERT, TinyLLaMA, Phi-3 |
| Embeddings / vector models | ✅ Yes | Sentence Transformers, Instructor models |
| Reinforcement learning models | ✅ Yes | RLHF-trained agents, PPO configs |
Classical ML via sklearn |
⚠️ Limited | A few examples exist, mostly for educational/demo purposes |
| XGBoost / LightGBM | ⚠️ Rare | Not commonly hosted, but can be wrapped into pipelines |
| Rule-based or statistical models (e.g. Naive Bayes) | 🚫 Not really | Usually too simple or not practical to share as models |
Building a Homemade Model?
Creating your own model from scratch is not just possible, it’s educational. Now I’m not just talking about a linear equation, here but a full-blow neural net! Code Academy has a nice tutorial on how to get start with building a neural net.
Here’s a general overview of the steps required:
- Data: Collect or curate a training dataset
- Framework: Use PyTorch, TensorFlow or JAX
- Compute: A GPU (local or cloud)
- Training: Run an optimisation loop with SGD or Adam
- Evaluation: Monitor accuracy, loss, perplexity
- Packaging: Export via ONNX or torchscript
You could build:
- A sentiment classifier
- A chatbot on your internal docs
- An image recogniser for niche applications (e.g. insects!)
How to access and run complex Models
If you want to run or access an LLM or other complex model acquired from Hugging Face or developed locally, there are several options. Each has tradeoffs around power, cost, and privacy.
1. OpenRouter
OpenRouter is a gateway that routes your query to various models via a unified API.
- ✅ Easy integration and flexible model access
- ✅ Fast and reliable
- ⚠️ Still cloud-hosted: less control over data privacy
- ⚠️ Costs per token or per request
2. Hosting Locally on Your Laptop
Running smaller models like Phi-3-mini or Gemma 2B on a laptop is increasingly feasible.
- ✅ Full privacy: data never leaves your machine
- ✅ Free after setup
- ⚠️ Limited power: can’t run massive models
- ⚠️ Requires technical setup e.g. Ollama or LM Studio
3. GPU-Enhanced Machine (eBay Special)
You can buy a new or used GPU workstation (e.g. with an NVIDIA RTX 3090 or A6000) and run even mid-sized models locally.
- ✅ Excellent balance of performance and control
- ✅ Ideal for hobbyists and researchers
- ⚠️ Expensive upfront cost, noisy and power-hungry
- ⚠️ Requires maintenance, Linux knowledge helpful
Great for models like:
- Mixtral, LLaMA 3 8B, stable diffusion models
4. Hourly Cloud Compute
Platforms like RunPod, Paperspace and LambdaLabs let you spin up a GPU machine by the hour.
- ✅ On-demand power for training or inference
- ✅ No hardware investment
- ⚠️ Pay-as-you-go can become expensive
- ⚠️ Privacy risk depending on provider/data handling
Used for:
- Fine-tuning models
- Serving open-source models via APIs
- Experiments with reproducibility
5. Commercial APIs
The easiest route is to use models via APIs from the big players:
-
OpenAI’s GPT-4o
-
Anthropic’s Claude 3
-
Google’s Gemini 1.5
-
✅ Fastest time to value
-
✅ Extremely powerful models
-
⚠️ Black-box: no insight into training or operation
-
⚠️ Data may be logged (unless on enterprise tiers)
-
⚠️ Pay-per-use, costs can scale fast
6. Enterprise ML Platforms
Platforms like Snowflake ML, Amazon SageMaker and MLFlow provide integrated environments for model development, deployment and management at enterprise scale.
- ✅ End-to-end ML workflow management
- ✅ Built-in security and governance
- ✅ Seamless data integration
- ⚠️ Requires enterprise licensing/subscription
- ⚠️ Platform lock-in considerations
Good for:
- Large-scale ML deployments
- Teams needing governance and security
- Organisations with existing data warehouse investments
- Integrated data pipelines
- Compliance and governance controls
- Collaboration features
- Production-grade reliability
The key difference from the other categories is that these platforms provide a complete ecosystem rather than just model hosting or computation resources. They’re especially valuable for organisations that already use these platforms for data warehousing and analytics.
The LLM-ification of everything (and why it’s a Problem)
Large Language Models are incredibly capable, they can summarise, classify, generate, reason and even write code. Given that power, it’s no surprise that many developers are now reaching for LLMs as the default tool for every ML problem.
But just because you can use an LLM doesn’t mean you should.
🚀 Why Everyone’s Using LLMs for Everything:
-
Low barrier to entry You don’t need to collect data, train anything or understand ML theory. Just write a prompt and get results.
-
One tool for many tasks You can classify sentiment, summarize articles, translate languages and chat, all from the same API.
-
Faster prototyping Especially for startups and small teams, LLMs let you get a working product today.
-
Wide availability With tools like OpenAI, Claude, Gemini and OpenRouter, LLMs are just an API key away.
🧱 But Here’s the Problem: It’s Becoming a Crutch
Relying on LLMs for everything creates several long-term issues:
1. Wasteful Overhead
You’re using a billion-parameter model to do what a 5MB model (or a few if-statements) could have done:
- Classifying tweets as positive or negative? A fine-tuned BERT or even fastText could do it faster and cheaper.
- Matching users to product categories? A logistic regression or decision tree might outperform your LLM at scale.
2. Scaling Costs
An LLM call might cost fractions of a cent, but multiply that by millions of users or messages and you’re bleeding money.
- Traditional models are nearly free to run once deployed.
- LLMs charge you every token, every call, every minute.
3. Latency
Even the fastest LLMs are slower than traditional models.
- A call to a hosted LLM takes 200ms–1s+.
- A local scikit-learn model returns results in milliseconds.
4. Loss of Specialisation
LLMs are generalists. That makes them useful, but also less sharp at domain-specific tasks than smaller, fine-tuned models.
- A fine-tuned fraud detection model trained on your data will almost always beat an LLM trying to “reason” its way to a result.
5. Skills Atrophy
When LLMs become a catch-all, developers stop learning about classical ML, statistics, feature engineering or model evaluation. That’s dangerous in regulated, high-stakes or performance-sensitive environments.
🧩 Why This Happens Anyway: Developer Psychology
- LLMs feel like magic. It’s easy to get hooked on the dopamine hit of seeing a prompt “just work.”
- Machine learning feels hard. Writing your own model or pipeline can seem intimidating, even when the task is simple.
- APIs are safe. You don’t have to manage GPUs, train models or even understand the data, just call the function.
So teams default to GPT for everything from customer support classification to bug triage to basic spreadsheet analysis, often without questioning if it’s the best tool for the job.
✅ When It’s Fine to Use LLMs for Traditional Tasks
To be clear, this isn’t a blanket indictment. Sometimes, using an LLM is totally appropriate, even if it could be done with classical ML.
Examples:
- You’re in a rush and need something working now
- You don’t have labeled data
- The job is small, infrequent or low-volume
- You want human-like flexibility (e.g. parsing vague or inconsistent text)
Good enough is good enough, when cost, latency and control don’t matter.
🔄 Consider a Hybrid Approach
Use LLMs for what they’re great at, language understanding, generation and reasoning. Use traditional models when you want:
- Speed
- Predictable output
- Privacy
- Simplicity
- Cost-efficiency
A good architecture might look like:
- Use LLMs at the edge, to route or clean messy data
- Pass that to a lightweight classifier or ranking model
- Return a response that’s fast, traceable and explainable