Glossary of AI Terms (with a focus on LLMs)
What follows is my attempt to explain AI through the medium of a glossary, with a focus on LLMs (Large Language Models). These aren’t Wikipedia definitions, but my take on what these terms mean. The purpose is to understand how LLMs can be used and the surrounding context. I’ll start with an AI hierarchy diagram and a slightly tongue-in-cheek definition of AI.
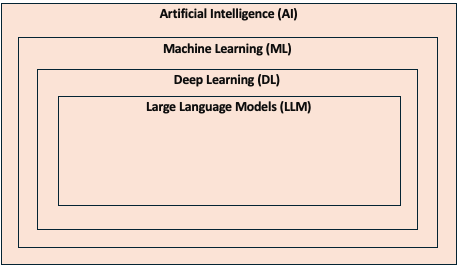
AI
AI is a buzzword, a marketing term, a label used to sell products and remain relevant in today’s world (at least in 2025). A rather cynical definition to start with, but one I feel should be pointed out before diving into a more technical definition. I say this because I often get asked why everything is labeled as “AI”, and my first response is, it’s the new “cloud”. Many people didn’t really understand what the cloud meant and still don’t. The same can be said of AI.
AI isn’t just a buzzword and there is real meaning behind it. There are many places where you can look this up, so I’ll just concentrate on one particular AI technique, and that is the Transformer Architecture. This technique has come to dominate in the last few years, mostly due to its most successful and notorious implementation, GPT.
ChatGPT uses GPT, which is a Large Language Model (LLM) but is also a Transformer Model. This is a type of deep learning, which is a branch of machine learning, which in turn is a subset of AI.
So, some healthy scepticism. When someone claims, “my product is AI enabled” or “… uses AI”, I usually assume one of three things:
- They are bluffing and don’t really know what AI means.
- It uses an AI technique that wouldn’t have been called AI two years ago.
- It uses an LLM such as GPT.
This assumption can be wrong, but if the label AI is applied to something without further explanation, it gives you a starting point to ask what is meant by “AI” when presented with a claim of its usage.
Large Language Model (LLM)
LLMs are pre-trained neural nets (an artificial brain) that are expensive to run and very expensive to build. They contain a lot of data and are created from vast amounts of human-created text. They can be used to write poetry, write computer code, pretend to be a dead relative, etc. In short, their utility is endless and the results look disturbingly clever.
GPT-4 is an example of an LLM. It is rumored to have cost £100 million to build and is “trained” on 1.76 trillion parameters. One example of the training data or the text that goes into GPT-4 is called Common Crawl. Common Crawl is a collection of data from 250 billion web pages, collected over the last 17 years.
Despite the huge cost to build and its almost human-like capability, most LLMs can be accessed via a chatbot for free or at a low monthly fee (typically $20 or less per month). All that endless power is democratically available to everyone and has been for the last two years. I feel like this is fundamentally why AI has been hyped up so much recently.
Relevant examples listed below are grouped by whether they are proprietary or open (hosted on Hugging Face). Each model is generally a family of models, and in each instance, I am referring to the latest or biggest unless specified otherwise.
All the models listed below are examples of foundation models. Foundation models are generally fine-tuned (turned into a fine-tuned model) before they can be used for applications like chatting or language translation. Without fine-tuning, models can be less useful and potentially dangerous.
Proprietary Models
| Model | Description | Size (in parameters) |
|---|---|---|
| GPT | Models from “Open” AI (yes, the quotes are deliberate). Forms the backend to ChatGPT and Copilot (tools that I use). | 1.76 trillion (GPT-4) |
| Gemini | Models from Google that power the Gemini assistant. Competes with GPT. | Unknown but rumored to be 1.56 trillion (Gemini Ultra). |
| Claude | From Anthropic. Known for being safe and ethical. | Unknown but rumored to be 2 trillion (Claude 3 Opus). |
All three of these models are comparable and have various strengths and weaknesses. Different sources will claim that one is better than the others; however, Claude appears to beat the others in IQ tests and is often regarded as generally outperforming GPT and Gemini.
Open Models
These models are generally smaller than proprietary models, so they may be less capable but are still good enough for many applications. Because they are smaller, they don’t require as large an investment to build and therefore can be given away for free and may be easier to include in a commercial product.
See Hugging Face Models for a canonical listing.
| Model | Description | Size (in parameters) |
|---|---|---|
| BLOOM | From Hugging Face. | 176 billion |
| Llama | Models from Meta. | 70 billion |
| Mistral | Models from Mistral. | 141 billion (Mixtral 8x22B) |
| Gemma | Smaller models from Google built similarly to Gemini. Notable for being small enough to run at home. | 7 Billion |
Hugging Face
Hugging Face is a website, a bit like GitHub, that hosts LLM models, tools to build LLM models, and tools to make use of LLM models. Everything is free and community maintained.
LLM Apps
ChatGPT (again with the ChatGPT) is an example of an LLM app. It hosts a user interface that allows a human to interact with a fine-tuned LLM model by asking questions of the LLM and responding with relevant answers.
You can also interact with LLMs via an API. This allows you to build whatever you like on top of the LLM and potentially build an AI agent. This is an application that performs intelligent tasks on your behalf, such as looking up train times or today’s weather.
AI Agents
AI agents are systems that don’t just answer questions, they can take actions. They’re set up to reason through tasks, use tools (like APIs or databases) and make decisions step by step. Instead of being passive responders, agents can actively do things to reach a goal.
For example, if you ask, “What’s the next train to Winchester?”, an agent could break that down into steps: call a rail API, parse the response and reply conversationally. Frameworks like LangChain make this possible by letting you chain together the model with external tools, memory and logic.
Transformer
The foundational tech behind modern AI models like GPT. A transformer model doesn’t just process words in order, it pays attention to how words relate to each other across a sentence or paragraph. This is what allows it to “get the vibe” of what you’re saying, understand context and generate more coherent, relevant responses.
Transformers work by assigning different weights to different words, so the model knows what to pay attention to. That’s why it can understand “He said she left” and know who “she” is.
Prompt Engineering
This is the art and science of getting useful, reliable answers out of an AI model by carefully crafting your input. It’s not just about asking a question, it’s about setting up the AI with the right instructions, tone, context and examples.
Think of it like briefing a new intern. The clearer and more specific you are about what you want, the better the result. “Act like a friendly tutor and explain this in simple terms” is a prompt. “Write a formal summary using bullet points” is another. Being vague gets you vague.
Context Window
This is the model’s short-term memory, or the amount of information it can “see” at one time. It’s measured in tokens (more on that below), and once you hit the limit, it starts forgetting earlier parts of the conversation.
For example, if the context window is 8,000 tokens (roughly 6,000 words), anything before that gets trimmed or dropped. That’s why long chats might make it lose the plot unless you keep reminding it what matters.
Tokens
Tokens are chunks of text that AI models read and write. A token is usually a word like “cat” or part of a word, if the word is complex, less common or made up. For instance, “chatting” might be split into “chat” and “ting.” Models don’t count words, they count tokens.
This matters because most AI tools charge based on token usage, not time or number of questions. So a long, detailed prompt or a massive output will cost more in tokens. It’s like a pay-per-word messaging service.
Fine-tuning
Fine-tuning means training a base model (like GPT-4) on your own data so it becomes an expert in your domain. Examples of domains are legal language, medical reports or your company’s internal docs.
Instead of starting from scratch, you build on the model’s general knowledge by feeding it new, specific examples. It’s a more permanent change than just giving it a long prompt or extra documents.
RAG (Retrieval-Augmented Generation)
RAG combines a language model with a document search system. Instead of guessing answers from memory alone, the model retrieves relevant content from a trusted source (like your SharePoint, Notion, or internal wiki) before responding.
This helps keep answers grounded in real facts. It’s like giving the model a chance to “Google” your knowledge base first, then write the answer. It massively reduces the risk of hallucination.
Hallucination
This is when an AI confidently makes stuff up—like quoting fake sources, inventing statistics or asserting untrue facts. It’s not malicious, the model is just trying to complete the pattern of language in a plausible way.
That’s why you always need to fact-check anything important (like an AI-generated glossary on AI terms 😂). LLMs don’t know what’s real. They just know what sounds right. Treat it like a very persuasive friend who occasionally bluffs.
Temperature
Temperature is a setting that controls how creative or predictable the AI’s responses are. Lower temperatures (like 0.2) make it more focused and factual. Higher ones (like 0.8 or above) make it more creative, chatty or random.
It ranges from 0 to 1, and a lower temperature essentially makes those tokens with the highest probability more likely to be selected. A higher temperature increases a model’s likelihood of selecting less probable tokens.
If you want safe, consistent answers (like summarising policy documents), go low. If you want it to brainstorm or write poetry, go higher. It’s like turning up the imagination dial.
Zero-shot Learning
This is the model’s ability to perform tasks it’s never been explicitly trained on, just by guessing based on patterns it has seen. For example, it might be able to write a product description even if it’s never been taught how, because it’s seen thousands of similar examples.
It’s like asking someone to write a press release for the first time. They might not have training, but they’ve read enough to figure it out.
Chain-of-Thought
This is a prompting technique that encourages the AI to “show its working” rather than jumping straight to an answer. It’s especially useful for solving logic puzzles, math problems or complex reasoning tasks.
By breaking a problem into smaller steps, the model is more accurate and transparent. You might say, “Let’s think step by step” or “First explain the logic, then give the answer.” Just like in school, showing your reasoning helps prevent silly mistakes.
Embeddings
This is an under-the-hood topic. Embeddings are numerical representations of words, sentences or documents that capture their meaning in a mathematical form. They let the model compare concepts by “distance” in meaning, not just exact wording.
For example, “cat” and “kitten” will be closer in embedding space than “cat” and “car.” This is how semantic search works, so when you search “how do I fix login issues,” it can also find documents titled “authentication problems.” It’s the backbone of search, clustering and classification in AI systems.
Vector Database
A vector database stores information in a way that makes it easy to find things based on meaning, not just keywords. Instead of saving raw text, it saves embeddings (see above) and lets you search by similarity.
So if you ask “how to reset my password,” it can retrieve articles that don’t contain those exact words but still mean the same thing (like “recover account access”). Tools like Chroma DB, Pinecone or Weaviate are popular vector databases used in AI apps to power smarter search, especially in Retrieval-Augmented Generation (RAG) systems.